Intro to AS/400
1 : แนะนำตัว AS/400
ทำไม คนส่วนใหญ่ เรียก AS/400เพราะ มันเป็นรุ่นที่ "ขายได้จำนวนมาก" (ทุกอย่างลงตัวพอดี จำไว้ตอบ คนช่างสงสัย)
มันรวมทุกอย่างไว้ที่ตัวมันเอง (ทั้ง Hardware และ Software)
- จบทุกอย่างด้วย "เจ้าเดียว"
# ยุคนั้นจะทำอะไร ต้องแยกซื้อ (อยากได้ Tape ความเร็วสูงยี่ห้ออื่นมาใช้)
มันมักจะเกิดปัญหา ต่อกันกับ ยี่ห้อที่เรา มีอยู่ "ไม่ได้"/"ยุ่งยาก"
ยุคนี้ โชคดี เกิดมาตฐาน USB Port
(แต่ยังวุ่นวาย ส่วนที่เหลือ เช่น หา Driver ที่ตรงกับ รุ่นอุปกรณ์ ,รุ่นของ Window + Patch)
- IBM สร้างทีมสนับสนุน และ การันตี ที่ "ดีเลิศ"
# เคยเจอะปัญหานี้มั๊ย ลง Excel 2016 แทน Excel XP แล้วเครื่องช้ามากๆๆๆ
สาเหตุ จากอะไร ? - เครื่อง PC รุ่นเก่าไป, RAM ไม่พอ, Win (ลงผิด,Patch ไม่ทันสมัย), ตัว Excel ลงผิด version, ใช้ Excel ผิดวิธี)
จะถามใครดีล่ะ ? คนนั้น(มักจะ)รู้เฉพาะงานของเขา มักจะบอกส่วนของฉัน ปรกติ ให้ไปถามคนอื่นต่อ ?
เราอยากจะทำงานต่อแล้วล่ะ ? ไปต่อไม่ถูกเลย
สุดยอด AS/400 IBM ทำเอง "ทั้งหมด" จึงตอบได้ ว่าปัญหา เกิดจากอะไร ? แก้ไขอย่างไร ? (รวมทั้งเตือนว่า ต้องปรับ อะไร? เพื่อไม่ให้เกิดปัญหา)
แต่ทั้งหมด ต้องแลก กับ "ราคา" และ "ค่าบริการ" ที่แพงเอาการ (IBM เรียกว่า เหมาะสม เพราะถ้าคุณทำงานต่อ ไม่ได้,ช้า มันมีมูลค่าสูงกว่า
ทำไม หลายบริษัทฯ ยังไม่เปลี่ยน ?
อารมณ์เดียวกับมีคนมบอกให้เปลี่ยน Win XP (เป็น 2000,Vista, 7,8,10)
แล้วเกือบทั้งโลก ก็ไม่ยอมเปลี่ยน
เพราะ มันใช้งานหลักได้ดี (เสียเงินเปลี่ยนทำไม) การเปลี่ยน "ต้องหยุด/ชะงัก" (ขณะเปลี่ยนต้องหยุด, ไม่นับรวมว่า ขณะเปลี่ยนเกิดปัญหา - อันนี้หยุดใช้ "ยาว", หลังเปลี่ยน ก็ต้อง "หัดใช้"=เสียเวลา) (เราไม่เคยหยุด)
การเปลี่ยน "ต้องจ่ายซะด้วย" (นับว่าแพงมาก)
หลายบริษัทฯ เลือกที่จะใช้งานต่อ จนกว่า จะไม่มี ข้ออ้างเหลือแล้ว
Hist รุ่นที่ IBM ผลิตบางส่วน (อาจจะเห็นคำพวกนี้)
- S/38(1978) -> ... -> AS/400(1988) -> (เปลี่ยนชื่อ) -> System i (สุดท้าย นำไปใส่ในตู้)




2 : Sign On & Sign Off
คอมพ์ ทุกชนิดจะต้องมี OS (Operating System) เป็นชุดโปรแกรมแรก ที่ทำงาน และเราก็ต้องคุยผ่านโปรแกรมตัวนี้ (ของ PC ก็คือ Windows หรือ Linux นั่นเอง)AS/400 เรียกเป็น OS/400
เมื่อจะเริ่มเข้าใช้ ระบบฯ เราจะต้อง "มีหน้าจอ" ที่ติดต่อกับ OS/400 ได้ (ภาพ S/38 จะเห็นว่า มีจอภาพ) ปัจจุบัน เข้าใช้ผ่าน CA/400 (ติดตั้งบน PC แล้วตั้งค่าให้มันติดต่อไป OS/400)
(ทั่วไป) เฉพาะ คนที่มีสิทธิ จึงจะเข้าใช้งานได้ โดย "ระบุตัวตน" ( ได้ทะเบียน โดย Admin หรือ เจ้าของเครื่อง แจ้งไว้)

อย่างน้อย ต้องระบุ User Name + Password
ถ้าหน้าจอมีช่องให้ระบุ อาจระบุเพิ่มเติม ได้
เช่น หลังจากผ่านหน้าจอ แล้ว เรียกใช้ Menu หรือ โปรแกรม อะไร (อยู่ใน Library อะไร)
ทำไม ต้องระบุชื่อ Menu,โปรแกรม ล่ะ ?
(แนวคิด IBM) จัดกลุ่ม โปรแกรม แยกเมนูไว้ เมื่อใช้งานจริง เกิดเมนู มากมาย จนเข้าใช้ตามลำดับ มัน "ช้า" มาก (ใน SAP ก็เหมือนกัน)
มันจะดีกับ User กลุ่มหนึ่ง ถ้า เข้าใช้ตรงๆ ตั้งแต่ตอนเข้าที่ SignOn ได้เลย
- แนวคิดเน้นทำงาน "ได้เร็ว" สำคัญกว่าเน้น "สวยงาม"

Command Line - พื้นที่ที่ใช้ป้อน "คำสั่ง" หรือ "ตัวเลือกเมนู"
การจบการใช้งาน ต้องป้อน คำสั่ง SignOff (ถ้าเป็นเมนูข้างต้น ป้อน 90)
User Profile and Assistance Levels
Assistance Level ผมจะเรียกว่า ระดับ "ตัวช่วย" ตามสิทธิการใช้คำสั่ง OS/400
(ผมว่า ง่ายดี) ในยุคแรกๆ แบ่งไว้แค่ 3 กลุ่ม คือ User, Programmer, Admin
ปัจจุบัน การจัดกลุ่ม เริ่ม "ซับซ้อน" เช่น User บางคน อยากเรียกใช้ คำสั่ง บางส่วนเหมือน Programmer (บางคนจะเรียกว่า Power,Advance) กลุ่มงานมีแยกเป็น เกี่ยวกับ เรื่อง File, Device, Spool, ... ทำให้การจัดกลุ่ม "ซับซ้อน" สุดๆ (ใครทำ เรื่องนี้ได้ดี นับว่าสุดยอดครับ)
3 : การใช้ Keyboard
AS/400 ถูกออกแบบให้ ป้อนได้ "เร็ว"โดยมือขยับน้อยที่สุด และไม่ต้องใช้ Mouse (ยุคนั้นไม่มี Mouse) ภายใต้ "ข้อจำกัด" จึงมีการสร้างวิธีเพื่อช่วย การรู้/เข้าใจ จะช่วยให้ จะทำให้เราทำงานเร็วขึ้น (ผมว่า ยุคนั้น พยายามได้สุดยอด และ ก็ยังมีประโยชน์ ถ้านำมาใช้)การป้อนข้อมุลจำนวนมาก จะต้องออกแบบ ให้ทำงานได้เร็ว
- เอกสาร + ลำดับการป้อน "หน้าจอ" จะต้องเรียง เหมือนกัน!
- ช่องที่จะป้อน จะเรียงลำดับ (เหมาะสำหรับกดปุ่ม [Tab] ไว้) กับ ตำแหน่งแหน่ง "มือ" ได้แบบเร็ว
ปุ่ม [Tab] ใช้ "ข้าม" ช่องป้อนไปช่องถัดไป (ถอยกลับ กดปุ่ม [Shift] ค้างไว้แล้วกด [Tab])
- เร็วกว่า กด ปุ่ม ลูกศร (ซ้ำๆๆๆๆๆ) หรือ ย้ายไปจับ Mouse
ปุ่ม [Field Exit] ถือว่า ป้อนข้อมูลช่องนั้น "เสร็จ" และให้ขยับไป ช่องถัดไป
กรณีป้อนตัวเลข จะสั่งขยับ ตัวเลขชิดขวาให้
คนรุ่นเก่า อาจจะตั้ง keyboard ให้เป็น ปุ่ม [Enter] เพราะใช้บ่อย
ปุ่ม [Ctrl] ด้านขวา จะตั้งค่าเป็น [Enter] แทน
ปุ่ม Function Key (แถวบน คีย์บอร์ด) ใช้แทน คำสั่งที่ใช้บ่อย (สามารถตั้งค่าได้)
F1,F3 = Exit ยกเลิก (มักใช้) สิ้นสุด คำสั่ง/โปรแกรม
F4: = Prompt คล้ายกับ Help ถ้าป้อนคำสั่งบางส่วน กด Prompt จะแสดงรายละเอียดคำสั่ง
F9: = Retrieve ดึงคำสั่ง ก่อนหน้ามา (ช่วยป้อน)
F12: = Cancel ยกเลิก (มักใช้) ยกเลิก การทำงาน step ล่าสุด (อาจจะมีหลาย step)
ปุ่ม Attention (CA/400 ส่วนใหญ่ จะตั้งไว้ที่ ปุ่ม [Esc]) สามารถตั้งค่าได้เช่น เปิดใช้ Command Line ใหม่ (ซ้อนหน้าจอ มุมขวาบนจะบอก ระดับการเรียก)
ปุ่ม System Request (CA/400 ส่วนใหญ่ จะตั้งไว้ที่ ปุ่ม [Esc] + Shift)
ใช้เพื่อติดต่อ กับ OS (คำสั่งพื้นฐานจำเป็น) เช่น เปิดจอที่ 2, ดู Message, SignOff
ปุ่ม PageUp, PageDown เลื่อนหน้าจอ กรณีข้อมูล มีมาก (หลายหน้า)
4 : Managing Your Work
การจะจัดการงาน (เรียกโปรแกรมป้อน, ขอดู Message , สั่งพิมพ์ ,สั่งย้าย Spool, ...)
ก็ต้อง รู้/เข้าใจ พื้นฐาน การทำงาน ก่อนน๊ะครับ
ชื่องานที่ทำอยู่ - จะต้องบอกให้ครบ ตามนี้
- Job (ชื่อจอ ,ชื่อที่ตัวเอง ตั้งไว้)
- User Name (ที่ SignOn)
- Number (เลขที่ Run No)
ถ้าทำงาน ไม่พิสดาร มีเทคนิคที่ ทำให้ บอก "ชื่อสั้นๆ" ได้
เช่น User ชื่อนี้ (ณ.เวลานี้) ใช้คนเดียว เปิดใช้หน้าจอเดียว ไม่สร้างอะไรใหม่ในช่วงนี้
ใช้ชื่อ จอ หรือ ชื่อ User Name (ตัวใดตัวหนึ่ง ก็พอ - แต่กลุ่มนี้ มีน้อยครับ)
ถ้าการใช้งาน ที่ซับซ้อนขึ้น การชี้ "ชื่องาน" ต้องบอกให้ครบ เช่น
- PC นี้ เปิดใช้หน้าจอ และ เป็น Secondary Screen (บริษัทผมเรียก กลับหน้าจอ)
- PC นี้ User Name เปิดใช้ 3 หน้าจอ 3
- User Name เปิด หน้าจอ ที่ 3 PC
 ภาพแสดง "ชื่องาน" (ดูได้ เมื่อเรียก System Request + 3)
ภาพแสดง "ชื่องาน" (ดูได้ เมื่อเรียก System Request + 3)
 ภาพแสดง Message ที่เตือนว่า "ชื่องาน" ทำอะไร ? เป็นอย่างไร ?
ภาพแสดง Message ที่เตือนว่า "ชื่องาน" ทำอะไร ? เป็นอย่างไร ?
งานใน OS/400 แบ่งเป็น 4 ชนิด (เวลาถาม ให้บอกว่า คุยเรื่องอะไรก่อน)
- งานชนิด Interactive (งาน ที่ใช้ผ่านหน้าจอ)
- งานชนิด Batch (ทำงานเบื้องหลัง - ไม่มีหน้าจอ)
- งานชนิด Communication
- งานชนิด System (Message, Spool File หรือ รายงาน, ...)


5 : Explore the System
Object = ชื่อ/คำ (ยาว 10 อักษระ) เช่น ชื่อคำสั่ง, ชื่อโปรแกรม, ...
Library = ที่เก็บ (จัดกลุ่ม) Object
# โปรแกรม,File ชื่อเดียวกัน อยู่ใน Library 2 ตัวได้ (ไม่ได้บอกว่า เป็น โปรแกรม,File ตัวเดียวกัน ที่ Copy ซ้ำ)
Object เป็น ได้หลายชนิด ดูชนิดได้จาก Object Type
เช่น Program (*PGM) , File (*FILE), Job (*JOB), Device (*DEV)
เช่น Program (*PGM) , File (*FILE), Job (*JOB), Device (*DEV)
ชื่อที่ไม่ควรไป "แก้ไข" คือ ชื่อที่ขึ้นต้นด้วย "Q","#" - เป็น Lib หรือ Obj ที่ IBM ใช้งาน
(คล้ายก้บ การที่เราไม่ควรเข้าไปยุ่งกับ C:\Windows)
เช่น QSYS, QIBM เป็นต้น
การใช้ คำสั่ง
ต้องจำครับ DspMsg = Display MessageStrPrtWrt = Start Printer Writer
EndWrt = End Writer
HldOutQ = Hold Output Queue
สังเกต ใช้อักษรย่อ 3 อักษรต่อ 1 คำ เริ่มต้นด้วย "กิริยา"
ใช้ตัวช่วยได้
- Dsp* (แสดงคำสั่งที่ขึ้นต้นด้วย Dsp)
- Go Tape (แสดงคำสั่งที่เกี่ยวกับ Tape)
Using Online Information
OS/400 มี Manual (คู่มือ) ที่ดีอยู่ในตัวมัน โดยเริ่มต้น กดปุ่ม [F1]
เช่น กด [F1] เพื่อสอบถาม หน้าจอนั้น, กด [F1] หรือ ป้อน ? ที่จุดที่ สงสัย
เช่น กด [F1] เพื่อสอบถาม หน้าจอนั้น, กด [F1] หรือ ป้อน ? ที่จุดที่ สงสัย
จะแสดง แบบย่อ และ สามารถดูเพิ่มได้
6 : Message
OS/400 (จนถึงวันนี้ยังพูดไม่ได้) จะคุยกับเราผ่าน Message เช่น "เฮ้ย! ป้อนคำสั่งผิด" (จริงๆ ไม่มี เฮ้ยน๊ะครับ), "คำสั่งนี้ทำงานเสร็จแล้ว" , "Printer มีปัญหา-กระดาษติด" เป็นต้น
หลายกรณี OS/400 รอ การทำงานของเรา และให้เราตอบด้วย เช่น ใส่กระดาษเสร็จแล้ว ทำงานต่อได้ เป็นต้น
Message ที่ OS/400 ส่งไป ต้องมี "ตู้เก็บ" Queue (เหมือนตู้จดหมาย)
มักจะสร้าง แยกตามหน้าที่ เช่น
QSYSOPR สำหรับส่งข้อความ เกี่ยวกับ OS เช่น Disk เต็ม, Tape ไม่ทำงาน, ...
ชื่อ User Profile สำหรับส่งข้อความ ไปยังบุคคล (ซึ่งอาจจะ ใช้พร้อมกันหลาย จอภาพได้)
ชื่อ จอ,WorkStation สำหรับส่งข้อความ ไปยังจอภาพ (ไม่สนว่า ใครใช้อยู่) เช่น โปรแกรมที่เรียกใช้ที่หน้าจอ นี้ ไม่สามารถทำงานได้
สังเกต การใช้หน้าจอ เมื่อขอดู Msg (DspMsg) ก็จะได้เห็น Message Queue 2 ตัว (User Profile, ชื่อจอ)
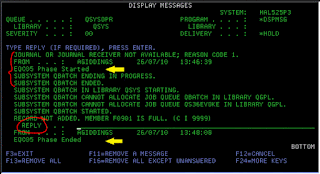
ตย. Msg ที่ QSYSOPR OS/400 มีอะไรจะบอก "มาก" (งานที่สำเร็จ และ มีปัญหา)
ผู้ดูแล จะได้เห็นทีละ "มากๆ" แล้ว ตอบ Msg (ตัวที่ OS ต้องการให้เราตอบ)
ตย. Msg ของแต่ละจอ เมื่อสั่งดู ก็จะเห็น "คล้ายกับ" QSysOpr แต่จะมีน้อยกว่ามาก

ตย. เมื่อ กด F1 เข้าไปใน Msg "แต่ละรายการ" ก็จะเห็น คำอธิบาย และ คำแนะนำการตอบ



สังเกต การใช้หน้าจอ เมื่อขอดู Msg (DspMsg) ก็จะได้เห็น Message Queue 2 ตัว (User Profile, ชื่อจอ)
ตย. Msg ที่ QSYSOPR OS/400 มีอะไรจะบอก "มาก" (งานที่สำเร็จ และ มีปัญหา)
ผู้ดูแล จะได้เห็นทีละ "มากๆ" แล้ว ตอบ Msg (ตัวที่ OS ต้องการให้เราตอบ)
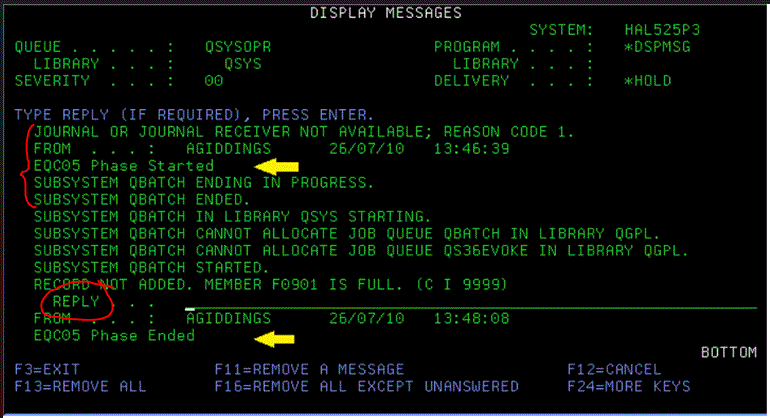
ตย. Msg ของแต่ละจอ เมื่อสั่งดู ก็จะเห็น "คล้ายกับ" QSysOpr แต่จะมีน้อยกว่ามาก

ตย. เมื่อ กด F1 เข้าไปใน Msg "แต่ละรายการ" ก็จะเห็น คำอธิบาย และ คำแนะนำการตอบ

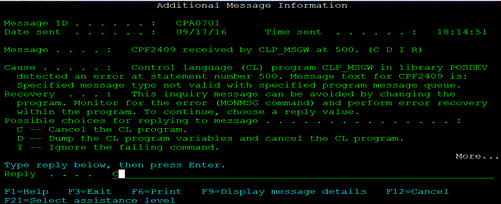
7. Log
ส่วนตัวถือว่า Log ใน AS/400 น่าสนใจมาก (เยอะมาก) และ จัดได้ดีระดับหนึ่ง
Log = รายการที่ OS/400 บอกเรา (คล้าย Message) ทั้งสิ่งที่มันทำ (Operate), งาน Security
เช่น (เมื่อเปิดเครื่อง) เกิดขั้นตอนอะไรบ้าง (สำเร็จ หรือ Fail - แค่แจ้งให้ทราบ / หยุดรอ)
(ตอนนี้) มีคน SignOn เข้าระบบ
Job 123456/User/DSP111 ถูกสั่งปิด โดย QPGMR
พบ Error(s) ขณะทำ ... (แจ้งให้ทราบ)
จอ DSP222 ไม่สามารถใช้งานได้ (C R) ... รอให้ตอบ (ยกเลิก / พยายามต่ออีกรอบ)
- ถ้าลืม เปิดครื่อง เปิดแล้ว กด "R"
File xxx/yyy เต็ม (C I R 99999) ... รอให้ตอบ
- ยกเลิก / ข้ามขั้นตอนไป=ไม่ write, พยายามใหม่ (ลดขนาดก่อน) , ขยายเพิ่มชั่วคราว)
มันจะทำงานแบบ "ทันที" (Real Time) - OS/400 ทำงานตลอดเวลา
ดังนั้น Log จะมีขนาดใหญ่ "มาก" - Admin ต้องคอย "จัดการ" ไม่ให้เต็ม
การจัดการเรื่องนี้ ใช้ทรัพยากรสูงมาก - หลายบริษัทฯที่ กำลังคนน้อย,ไม่มีเวลา จะไม่สนใจทำ
(log มาก ใช้เวลา "นาน" ,อ่านไม่ทัน ,ส่วนใหญ่แค่รับทราบ, บางเรื่องก็ไม่รู้ว่า "สำคัญ" หรือไม่ ? (ต้องไปอ่านเพิ่มเติม, ...)

ตั้งแต่ ค.ศ.2017 มีกฏหมายเกี่ยวกับ Security : ใจความสั้นๆ ตามนี้
- ต้องสามารถบอกได้ว่า มีใครเข้ามาใช้ระบบ (เมื่อไหร่)
ดูบันทึกย้อนหลังดูได้อย่างน้อย ... วัน
- (เกี่ยวกับ การเงิน) คนดังกล่าว เข้ามาใช้ ระบบ / Data อะไร ?
A: System i Navigator
เป็น Application พื้นฐาน แสดงเป็นรูปภาพ GUI (Graphic User Interface เหมือน Window)
ข้อดี สวยงาม, ไม่ต้องจำคำสั่ง ,จัดแบ่งเป็น Column , ค้นหาได้ง่าย
ข้อเสีย (เล็กน้อย) คือ ต้องตั้งค่าเริ่มต้น (ถ้าไม่ทำ จะมองไม่เห็น) ,ทำงานช้ากว่า ,คนที่จำคำสั่งได้ จะพิมพ์คำสั่งโดยตรง (เร็วกว่า)
สำหรับทุกคน (User, System Operator, Developer, Admin)
การติดตั้ง จะสามารถ "จำกัด" สิทธิการใช้ Menu ได้ (เช่น ไม่ให้ใช้ SQL เป็นต้น)
B: ศัพท์เทคนิค อีกสักนิด
- Job ที่เกิดขึ้นใน OS/400 จะต้องทำงานภายใต้ SubSystem
ถ้าไม่ได้ตั้งค่า จะมี SubSystem ชื่อ QBase เป็นตัวจัดการ ตัวเดียว หรือ ไม่อนุญาต
- เครื่องสำหรับ มีผู้ใช้งาน มากขึ้น IBM จะแนะนำให้ "แยก" ตามกลุ่มงาน และ Memory
เช่น QBath, Qinter, QSpool, ... เป็นต้น เพื่อให้ "งานในแต่ละกลุ่ม" ไม่ไปแย่ง Memory
- เมื่อ SignOn ผ่าน UserProfile ที่สร้างไว้ ได้กำหนด "ค่าเริ่มต้น" ของ "เส้นทาง" ไว้
ซึ่งจะวิ่งผ่าน Routing เพื่อแยกไปทำงานใน SubSystem แต่ละตัว
- รายละเอียด ที่กำหนดใน User Profile สามารถจัดกลุ่ม (อีกแล้ว) รวมเรียกเป็น Job Description (JobD) ทำให้เราสามารถ "set ค่าซ้ำ ให้กับ User Profile คนใหม่ได้"
- รายละเอียด ที่กำหนดใน User Profile สามารถจัดกลุ่ม (อีกแล้ว) รวมเรียกเป็น Job Description (JobD) ทำให้เราสามารถ "set ค่าซ้ำ ให้กับ User Profile คนใหม่ได้"
- ใน SubSystem แต่ละตัว ก็สามารถ กำหนดว่าจะให้ทำอะไร ก่อน "เริ่มงาน" หรือไม่ ได้
#พอก่อน รายละเอียดเต็มๆ ต้องไปดู Flow Chart - กว่าจะเกิด Job ใน OS/400
http://www.metrosystems.co.th/th/Products/Documents/Training/iSeries%20Introduction.pdf
https://www.slideshare.net/tvlooy/introduction-to-the-ibm-as400
https://www.scss.tcd.ie/SCSSTreasuresCatalog/hardware/TCD-SCSS-T.20121208.068/IBM-AS400-technical-introduction.pdf




{kind=link}